Retrieval Augmented Generation (RAG)
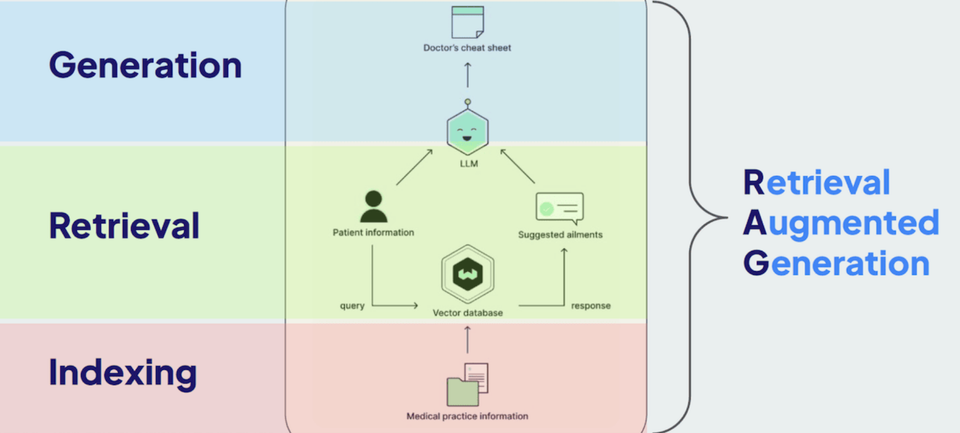
Retrieval-Augmented Generation (RAG) represents a groundbreaking leap in enhancing the capabilities of large language models (LLMs). This method combines the strengths of information retrieval systems with generative models, resulting in outputs that are more accurate, contextually relevant, and up-to-date. While LLMs are incredibly powerful in understanding and generating human-like text, they have a fundamental limitation: they are constrained by the static nature of their training data. These models are only as up-to-date as the point in time when they were last trained, making them unable to access real-time information or external knowledge sources.
In contrast to traditional methods that rely on rigid database queries, such as SQL, to retrieve structured data from predefined schemas, RAG dynamically integrates external knowledge sources—both structured and unstructured—into the text generation process. This hybrid approach combines the precision of information retrieval systems with the creativity of generative models, producing outputs that are not only more accurate and contextually relevant but also adaptable to real-time data.
Unlike SQL-based systems, which require extensive setup, predefined queries, and often struggle with unstructured or semi-structured data, RAG excels in flexibility. By leveraging vector search and semantic understanding, RAG enables LLMs to access and incorporate knowledge from diverse formats, including documents, web pages, APIs, and even real-time feeds. This augmentation overcomes the inherent limitations of LLMs, allowing them to perform tasks such as responding to complex customer support queries, summarizing the latest research, or generating personalized, timely content.
By bridging the gap between static training data and real-world, dynamic information, RAG enables the creation of AI systems that are both dynamic and deeply informed—opening up new possibilities for applications that demand real-time relevance and precision.
Benefits of RAG
- Improved Accuracy and Relevance: By accessing external databases or documents, RAG ensures that generated content is grounded in factual and current information, reducing the likelihood of errors or hallucinations [Pareto].
- Enhanced Contextual Understanding: RAG allows models to incorporate specific domain knowledge, leading to responses that are tailored to particular industries or subjects [Tonic]
- Dynamic Knowledge Integration: Unlike static LLMs, RAG can incorporate new information without the need for retraining, making it adaptable to rapidly changing data landscapes [Coveo]
- Reduced Hallucinations: By grounding responses in retrieved documents, RAG minimizes the generation of fabricated or misleading information [Wired]
Shortcomings of RAG [Kiteworks]
- Dependency on Retrieved Data Quality: The effectiveness of RAG is heavily reliant on the relevance and accuracy of the retrieved documents. Poor-quality data can lead to suboptimal outputs.
- Increased Computational Complexity: Integrating retrieval mechanisms with generative models adds layers of complexity, potentially leading to higher computational costs and longer processing times.
- Implementation Challenges: Setting up a RAG system requires sophisticated infrastructure and expertise, which may pose challenges for organizations lacking in technical resources.
- Potential for Information Overload: Retrieving excessive or irrelevant information can overwhelm the generative model, leading to less coherent or focused outputs.
Applications of Retrieval-Augmented Generation (RAG)
RAG is rapidly gaining traction across various domains due to its ability to combine the strengths of retrieval systems and generative AI. Here are some of the most prominent applications currently benefiting from RAG:
1. Healthcare
- Medical Diagnostics and Summarization: RAG systems can retrieve up-to-date medical research or patient records to assist doctors in generating accurate diagnoses or treatment summaries.
- Example: Creating personalized summaries for patients based on their medical history.
- Use Case: AI-powered tools like the RAG-based "Doctor’s Assistant" retrieve medical knowledge to support clinical decision-making.
2. Legal and Compliance
- Legal Research: RAG helps lawyers quickly find relevant case laws, statutes, and legal precedents to support arguments, reducing hours of manual research.
- Compliance Assistance: It aids organizations in retrieving up-to-date regulatory requirements and generating reports or summaries to ensure adherence.
- Example: Summarizing privacy regulations or retrieving compliance frameworks.
3. Customer Support
- Dynamic Knowledge Bases: Customer support systems use RAG to pull relevant information from company knowledge bases to answer user queries accurately and promptly.
- Example: Providing troubleshooting steps by pulling information from product manuals and user guides.
- Chatbots: Chatbots equipped with RAG can retrieve real-time, accurate responses to customer inquiries without pre-training on static datasets.
- E-commerce
- Product Recommendations: RAG enhances the accuracy of product recommendations by combining customer preferences with detailed product specifications or reviews.
- FAQ Generation: Automatically generating FAQs or product descriptions based on customer inquiries and catalog data.
Weaviate: An Open-Source Vector Database for RAG
Weaviate is a fully open-source vector database designed to facilitate the implementation of RAG systems. It enables efficient storage, retrieval, and management of vectorized data, which is essential for semantic search and retrieval tasks in RAG pipelines.
Key Features of Weaviate [Weaviate]:
- Scalability: Weaviate is built to handle large-scale vector data, ensuring high performance even with extensive datasets.
- Flexibility: It supports various data types and integrates seamlessly with different machine learning models, allowing for customizable RAG implementations .
- Open-Source Community: Being open-source, Weaviate benefits from continuous contributions and improvements from a global community of developers and researchers.
Weaviate effectively transforms diverse data inputs into vector representations, stores them efficiently, and facilitates advanced semantic search capabilities. The process of converting input documents into vectors and storing them involves several key steps:
1. Vectorization:
Weaviate integrates with various machine learning models to transform textual content into vector embeddings—numerical representations that capture the semantic meaning of the text. This process, known as vectorization, enables the system to understand and process the content effectively.
2. Data Structuring:
To enhance retrieval accuracy, especially for extensive documents, the content is often divided into smaller, manageable chunks. Each chunk is then vectorized individually, allowing for more precise search and retrieval operations.
3. Storage:
- Object Storage: Weaviate stores both the original data objects and their vector embeddings within its database. This dual storage ensures that the semantic meaning (captured by vectors) and the actual content are both readily accessible.
- Vector Indexing: Weaviate employs advanced indexing techniques, such as Hierarchical Navigable Small World (HNSW) graphs, to organize and manage the stored vectors. This structure facilitates efficient similarity searches, enabling rapid retrieval of semantically related data.
4. Retrieval and Querying:
- Similarity Search: When a query is made, Weaviate converts the input into a vector and searches for similar vectors within its index. This process allows the system to retrieve information that is semantically aligned with the query, even if exact keywords are not matched.
Implementing RAG with Weaviate
Weaviate's architecture is well-suited for RAG applications. It allows for the storage of vector representations of documents, enabling efficient similarity searches that are crucial for retrieving relevant information during the generation process. By integrating Weaviate into a RAG pipeline, developers can enhance the retrieval component, leading to more accurate and contextually appropriate generated content.
RAG variations
Retrieval-Augmented Generation (RAG) has evolved into various specialized approaches. Here are some notable variations:
- Active Retrieval-Augmented Generation (Active RAG)
This approach emphasizes dynamic interaction between the model and the retrieval system during the generation process. It iteratively refines queries in real-time to improve the relevance of retrieved information, enhancing the accuracy of generated responses. - Multimodal Retrieval-Augmented Generation (Multimodal RAG)
Multimodal RAG incorporates multiple data types—such as text, images, and videos—into the retrieval and generation process. This enables the model to generate richer and more contextually relevant responses by coherently interpreting diverse forms of information [NVIDIA]. - Corrective Retrieval-Augmented Generation (Corrective RAG)
Corrective RAG focuses on enhancing the factual accuracy of generated content. It cross-references outputs with reliable external sources, correcting any discrepancies to ensure the information is precise and trustworthy. - Knowledge-Intensive Retrieval-Augmented Generation (Knowledge-Intensive RAG)
This variation specializes in handling highly technical or domain-specific information. It integrates extensive external knowledge bases pertinent to specialized fields, enabling the generation of detailed and accurate content in areas requiring deep expertise. - Memory Retrieval-Augmented Generation (Memory RAG)
Memory RAG retains and recalls previous interactions to improve the quality, continuity, and personalization of future responses. By maintaining a memory of past dialogues, it enhances user experience through more coherent and contextually aware interactions [Weka].
Conclusion
Retrieval-Augmented Generation is becoming a cornerstone for applications that require contextually relevant and fact-checked outputs. Its ability to produce more accurate and contextually relevant outputs by leveraging external knowledge sources, opens the door to transformative improvements in industries ranging from healthcare to content creation. Tools like Weaviate play a pivotal role in facilitating the implementation of RAG systems, providing the necessary infrastructure to manage and retrieve vectorized data efficiently.
While Weaviate stands out as an easy to use and fully open-source solution for RAG workflows, there are other platforms like Milvus, Haystack, and Qdrant also offer robust features tailored for specific use cases. Choosing the right solution depends on the scale, performance requirements, and complexity of the RAG application in question.